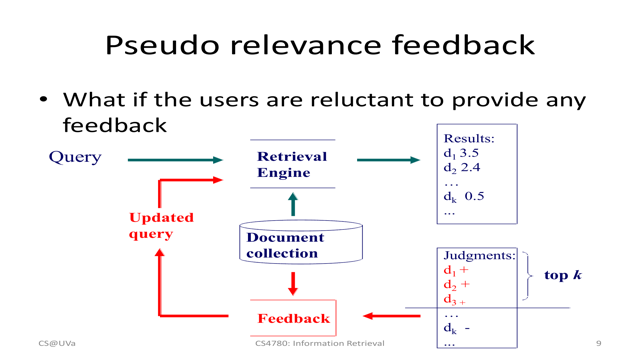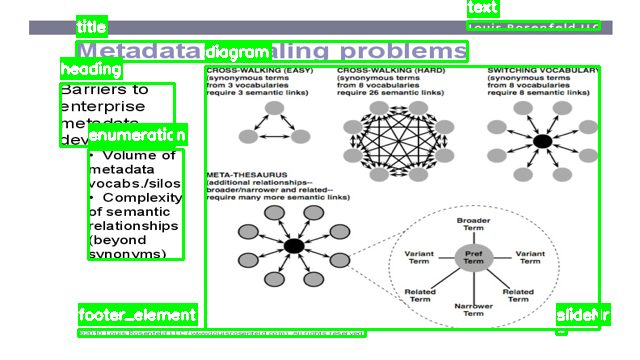


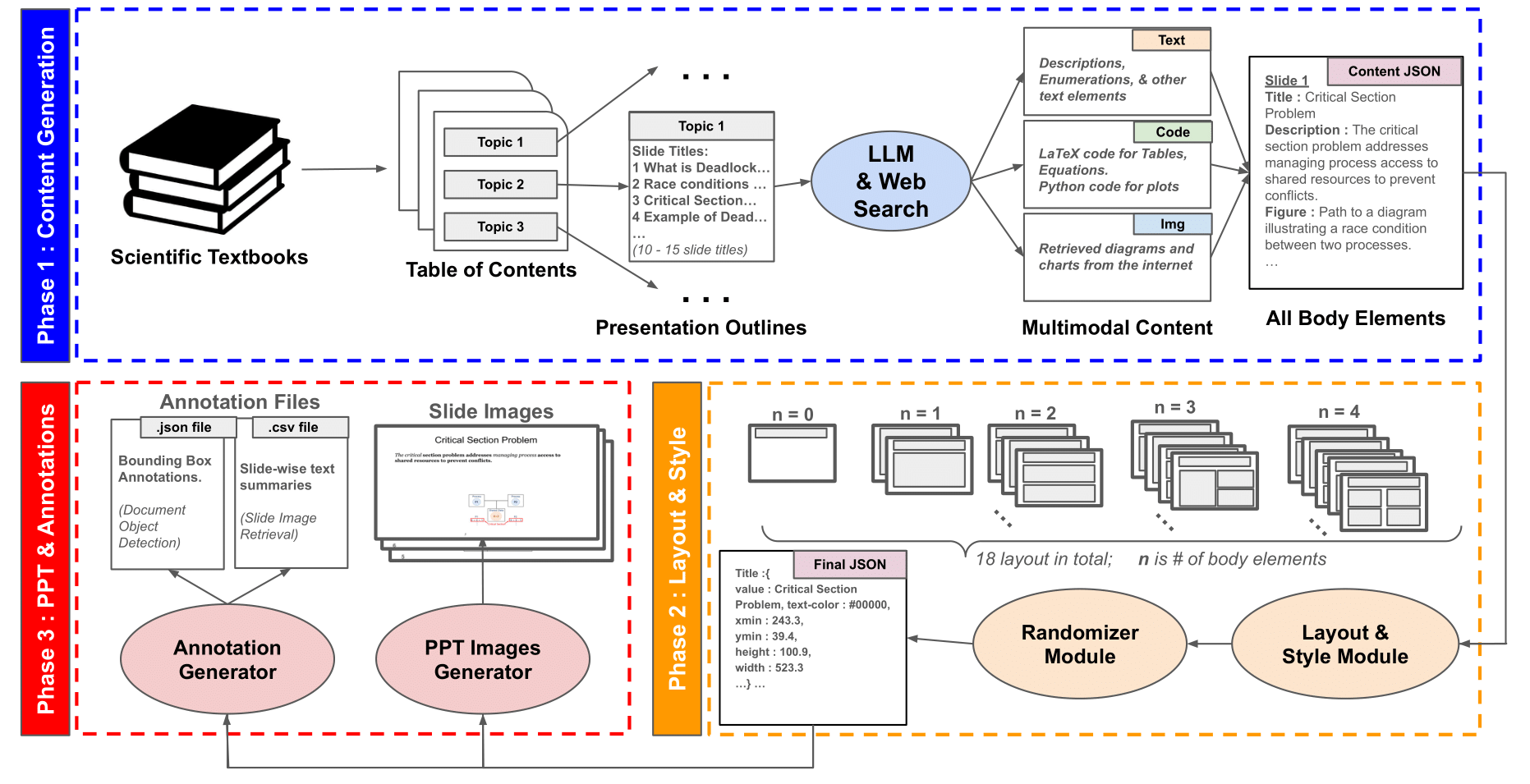
SynDet
SynDet is a subset of our synthetic slide dataset designed specifically for the Slide Element Detection (SED) task. It includes 2,200 slide images automatically annotated with bounding boxes in COCO format. These annotations span 16 fine-grained element categories, such as:
- Textual:
Title,Description,Enumeration,Heading - Structural:
Equation,Table,Chart,Code - Visual:
Diagram,Natural-Image,Logo - Meta:
Slide Number,Footer Element,URL - Captions:
Figure Caption,Table Caption
Annotations are extracted directly from slide structure JSONs and layout maps generated in the SynSlideGen pipeline, allowing pixel-accurate labeling without manual annotation. This provides a scalable solution for training and benchmarking object detection models on educational material.

![Effect of real slide images (RealSlide) on the performance (mAP@[0.5-0.95]) of three slide element detection models under two training strategies: (i) Single Stage and (ii) Two Stage](./static/images/slide_element_detection.png)